Comenzamos la tarea de analizar a los atletas profesionales mejor pagados importando las librerías de Python y el conjunto de datos que vamos a necesitar.
in[1]: import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="darkgrid")
plt.style.use("seaborn-pastel")
df = pd.read_excel("Forbes Athlete List 2012-2019.xlsx")
df.head()
out[1]: Rank Name Pay Salary/Winnings Endorsements Sport Year
#1 Lionel Messi $127 M $92 M $35 M Soccer 2019
#2 Cristiano Ronaldo $109 M $65 M $44 M Soccer 2019
#3 Neymar $105 M $75 M $30 M Soccer 2019
#4 Canelo Alvarez $94 M $92 M $2 M Boxing 2019
#5 Roger Federer $93.4 M $7.4 M $86 M Tennis 2019
Nuestro conjunto de datos contiene 7 columnas y 795 filas, vamos a describir cada una de sus características:
- Rank: Clasificación anual basada en los ingresos por año.
- Name: Nombre del atleta.
- Pay: Ingresos totales al año.
- Salary/Winnning: Ingresos por salarios al año
- Endorsements: Ingresos procedentes de la publicidad, medios de comunicación y patrocinadores al año.
- Sport: Deporte que practica el atleta.
- Year: Año
El conjunto de datos que estamos utilizando es de Forbes. Algunas columnas no son consistentes en el conjunto de datos debido a que Forbes ha agregado un # antes de los valores en la columna Rank. Vamos a arreglar esto y quitar el signo de dólar $ y M. Además, cambiamos los nombres de las columnas de nuestro conjunto de datos y el nombre de los deportes dentro de la columna Deporte para una mejor comprensión de nuestro conjunto de datos.
in[2]: df.Rank = df.Rank.apply(lambda x: int(x.split("#")[1]) if type(x) == np.str else x)
df.Pay = df.Pay.apply(lambda x: float(x.split(" ")[0].split("$")[1]))
df.Endorsements = df.Endorsements.apply(lambda x: float(x.split(" ")[0].split("$")[1]))
df["Salary/Winnings"].replace("-",'$nan M',inplace=True)
df["Salary/Winnings"] = df["Salary/Winnings"].apply(lambda x: float(x.split(" ")[0].split("$")[1]))
df.columns = ['Ranking', 'Nombre', 'Ingresos', 'Salario', 'Patrocinio', 'Deporte', 'Año']
df.Deporte.replace({"Soccer":"Fútbol", "Football":"Fútbol Americano", "Baseball":"Beisbol",
"Basketball":"Basquetbol", "Mixed Martial Arts":"MMA", "Auto racing":"Automovilismo",
"Auto Racing":"Automovilismo", "Tennis":"Tenis", "Boxing":"Boxeo","Basketbal":"Basquetbol",
"Motorcycle":"Motociclismo",
},inplace=True)
df.head()
out[2]: Ranking Nombre Ingresos Salario Patrocinio Deporte Año
1 Lionel Messi 127.0 92.0 35.0 Fútbol 2019
2 Cristiano Ronaldo 109.0 65.0 44.0 Fútbol 2019
3 Neymar 105.0 75.0 30.0 Fútbol 2019
4 Canelo Alvarez 94.0 92.0 2.0 Boxeo 2019
5 Roger Federer 93.4 7.4 86.0 Tenis 2019
Buscamos valores nulos en nuestro conjunto de datos y procedemos a eliminarlos
in[3]: df.isnull().any()
out[3]: Ranking False
Nombre False
Ingresos False
Salario True
Patrocinio False
Deporte False
Año False
dtype: bool
Podemos ver que la columna Salario contiene valores nulos. A continuación, buscamos más detalles:
in[4]: df[df["Salario"].isnull()]
out[4]: Ranking Nombre Ingresos Salario Patrocinio Deporte Año
520 79 Russell Westbrook 0.0 NaN 0.0 Basquetbol 2015
Nuestro conjunto de datos tiene una instancia con valores nulos. Procedemos a eliminarla usando el índice de dicha instancia.
in[5]: df.drop(520, inplace=True)
Finalmente, verificamos que nuestro conjunto de datos no tenga más valores nulos.
in[6]: df.isnull().any()
out[6]: Ranking False
Nombre False
Ingresos False
Salario False
Patrocinio False
Deporte False
Año False
dtype: bool
Ahora que nuestro conjunto de datos ya no contiene valores nulos podemos visualizar los atletas mejor pagados del mundo en base al deporte que practican
in[7]: df.groupby("Nombre").first()["Deporte"].value_counts().plot(kind="pie", autopct="%.0f%%",figsize=(15,15),wedgeprops=dict(width=0.4),pctdistance=0.8)
plt.ylabel(None)
plt.title("Atletas mejor pagados por deporte",fontweight="bold")
plt.show()
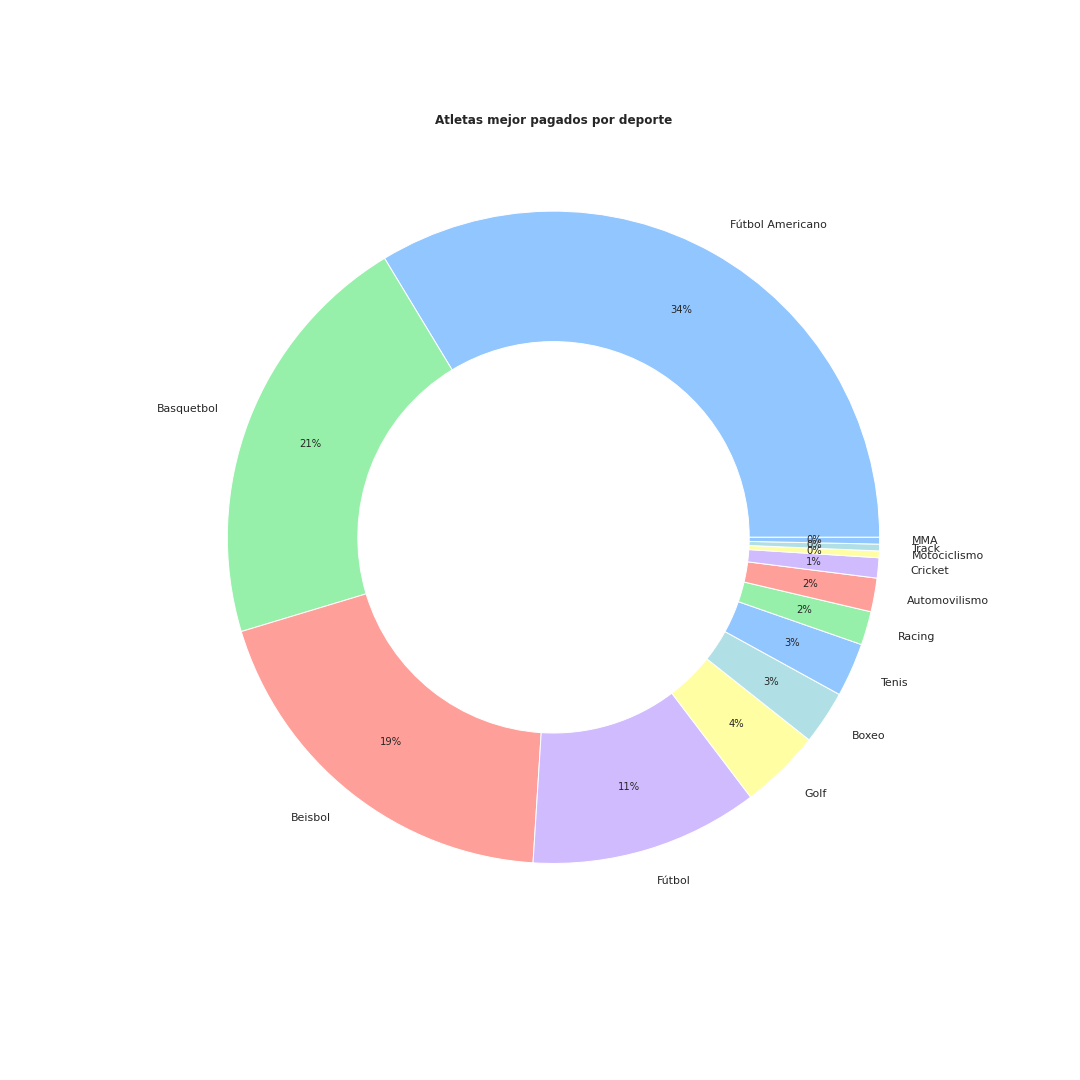
Algunos deportes representan menos del 1% del conjunto de datos. Procedemos a eliminarlos para una mejor visualizacion de los datos.
in[8]: df = df[(df["Deporte"] != "MMA") & (df["Deporte"] != "Track") & (df["Deporte"] != "Motociclismo")]
df.groupby("Nombre").first()["Deporte"].value_counts().plot(kind="pie",autopct="%.0f%%", figsize=(15,15),wedgeprops=dict(width=0.4),pctdistance=0.8)
plt.ylabel(None)
plt.title("Atletas mejor pagados por deporte",fontweight="bold")
plt.show()
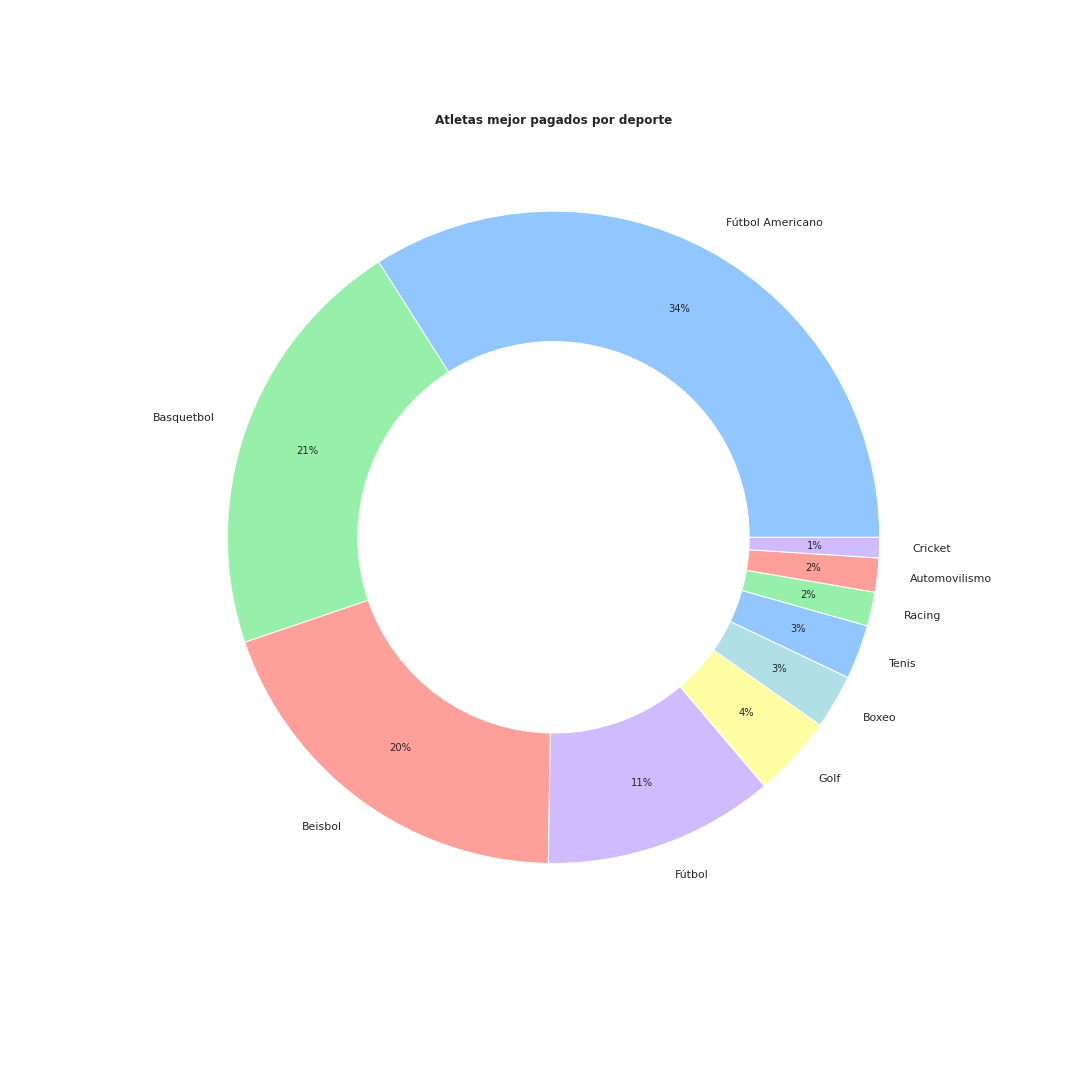
Para poder crear nuestra barra de animación del acumulado de ingresos de los atletas mejor pagados del mundo debemos convertir la columna Año en un objeto DateTime.
in[9]: df.Año = pd.to_datetime(df.Año,format="%Y")
Después, creamos una tabla dinámica donde las columnas están compuestas por los nombres de los atletas y los índices por los años.
in[10]: racing_bar_data = df.pivot_table(values="Ingresos",index="Año",columns="Nombre")
racing_bar_data.head()
out[10]: Nombre A.J. Burnett A.J. Green Aaron Donald Aaron Rodgers Adam Wainwright
Año
2012-01-01 NaN NaN NaN NaN NaN
2013-01-01 16.6 NaN NaN 49.0 NaN
2014-01-01 NaN NaN NaN 22.0 NaN
2015-01-01 NaN NaN NaN 19.1 19.8
2016-01-01 NaN 33.3 NaN NaN NaN
La mayoría de los atletas tienen valores NaN. Solo por curiosidad, veamos cuales son los atletas que aparecen de manera constante desde el 2012 en el Top 100 de los atletas mejor pagados del mundo.
in[11]: racing_bar_data.columns[racing_bar_data.isnull().sum() == 0]
out[11]: Index(['Carmelo Anthony', 'Cristiano Ronaldo', 'Dwight Howard',
'Justin Verlander', 'LeBron James', 'Lionel Messi', 'Phil Mickelson',
'Rafael Nadal', 'Roger Federer', 'Tiger Woods'],
dtype='object', name='Nombre')
Ahora vamos a interpolar los valores de forma lineal, y rellenaremos los valores NaN restantes con el método backfilling. El método bfill reemplaza los valores nulos con los valores de la siguiente fila.
in[12]: racing_bar_completa = racing_bar_data.interpolate(method="linear").fillna(method="bfill")
Después, convertimos los datos en una suma acumulativa de los ingresos de cada atleta a lo largo de varios años.
in[13]: racing_bar_completa = racing_bar_completa.cumsum()
racing_bar_completa.head()
out[13]: Nombre A.J. Burnett A.J. Green Aaron Donald Aaron Rodgers Adam Wainwright
Año
2012-01-01 16.6 33.3 41.4 49.00 19.8
2013-01-01 33.2 66.6 82.8 98.00 39.6
2014-01-01 49.8 99.9 124.2 120.00 59.4
2015-01-01 66.4 133.2 165.6 139.10 79.2
2016-01-01 83.0 166.5 207.0 175.75 99.0
A continuación, hacemos un muestreo semanal del conjunto de datos con una interpolación lineal para tener una transición suave en nuestra animación.
in[14]: racing_bar_completa = racing_bar_completa.resample("1D").interpolate(method="linear")[::7]
racing_bar_completa.head()
out[14]: Nombre A.J. Burnett A.J. Green Aaron Donald Aaron Rodgers Adam Wainwright
Año
2012-01-01 16.60 33.30 41.40 49.00 19.80
2012-01-08 16.92 33.94 42.19 49.94 20.18
2012-01-15 17.23 34.57 42.98 50.87 20.56
2012-01-22 17.55 35.21 43.78 51.81 20.94
2012-01-29 17.87 35.85 44.57 52.75 21.31
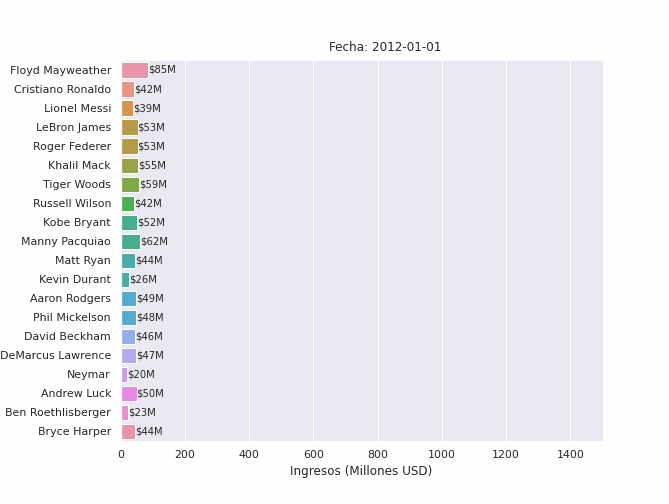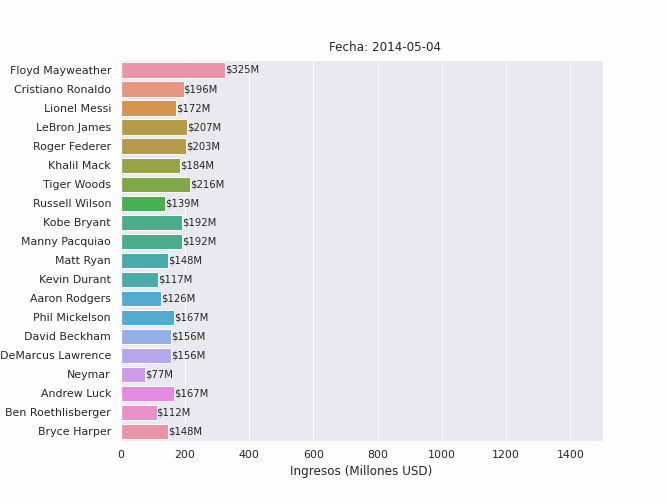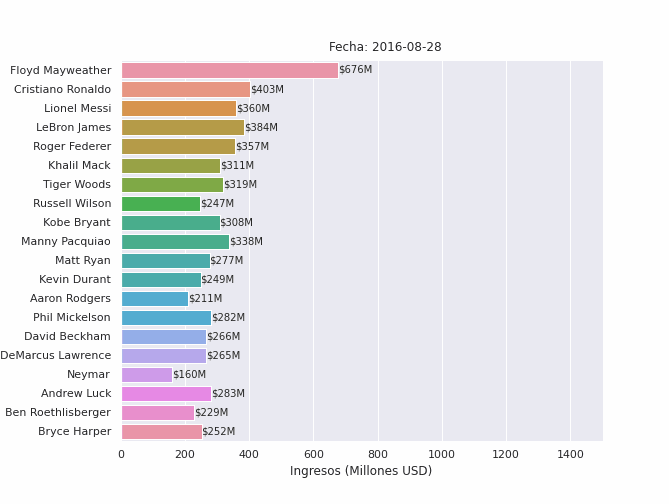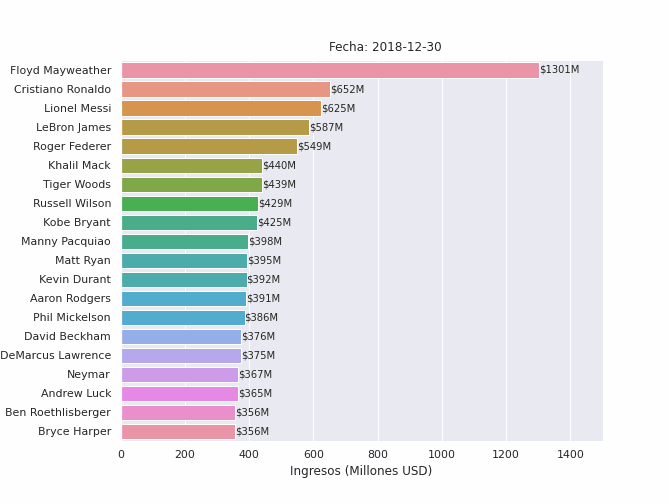
Finalmente, importamos los paquetes de Python necesarias para crear, ejecutar y guardar animaciones y sus elementos (líneas, barras, textos, etc.). El siguiente código generará una animación para los 10 atletas mejor pagados del mundo entre 2012 y 2019:
in[15]: from matplotlib.animation import FuncAnimation, PillowWriter
seleccion = racing_bar_completa.iloc[-1,:].sort_values(ascending=False)[:20].index
data = racing_bar_completa[seleccion].round()
fig,ax = plt.subplots(figsize=(9.3,7))
fig.subplots_adjust(left=0.18)
no_of_frames = data.shape[0]
#iniciamos el barplot con los valores de la primera fila
barras = sns.barplot(y=data.columns,x=data.iloc[0,:],orient="h",ax=ax)
ax.set_xlim(0,1500)
txts = [ax.text(0,i,0,va="center") for i in range(data.shape[1])]
titulo_txt = ax.text(650,-1,"Fecha: ",fontsize=12)
ax.set_xlabel("Ingresos (Millones USD)")
ax.set_ylabel(None)
def func_animacion(i):
#obtener fila
y = data.iloc[i,:]
#actualizar título de barplot
titulo_txt.set_text(f"Fecha: {str(data.index[i].date())}")
#actualizar elementos del plot
for j, b, in enumerate(barras.patches):
#actualizar medida de barra
b.set_width(y[j])
#actualizar texto de cada barra
txts[j].set_text(f"${y[j].astype(int)}M")
txts[j].set_x(y[j])
animacion = FuncAnimation(fig,func_animacion,repeat=False,frames=no_of_frames,interval=1,blit=False)
animacion.save('atletas-mejor-pagados.gif', writer='pillow', fps=120)
plt.close(fig)
Puedes descargar el cuaderno del projecto aquí